


1. Introduction
In recent years, the integration of machine learning (ML) into spine surgery has shown promise in enabling personalized risk predictions [1,2]. These advancements could improve patient outcomes, streamline surgical decision-making, reduce costs, and optimize medical management [3]. ML, a subset of artificial intelligence (AI), utilizes computer algorithms to efficiently solve intricate tasks. A notable advantage lies in its adaptability, enabling models to continually learn and be redesigned by incorporating new data and modifying their underlying knowledge.
Machine learning has witnessed significant advancements, notably in the realm of deep learning (DL)—an advanced subset that involves neural networks with multiple layers, enabling more intricate data processing and abstraction. This structure contributes to its capability to automatically learn and extract features from complex datasets [4]. The accumulation of advancements has garnered strong support from the industry, recognizing the substantial potential of ML and DL in enhancing medical research and clinical care [5]. However, despite the developments made in prediction models, their effective application in predicting uncommon outcomes remains limited in the literature. This brings attention to the class imbalance challenge in ML, where certain classes of interest occur far less frequently than others [6].
Imbalanced data essentially means that a dataset is skewed, leading to challenges with data generalizability, inadequate training of the ML model, and false positive readings. This issue is particularly relevant in medical ML models, where only a small proportion of individuals may experience a certain event, such as a specific condition or complication. In spine surgery, the outcomes of interest, such as readmission, extended length of stay, or specific complications, are considered infrequent events. In such cases, the integration of ML for personalized risk predictions becomes trickier, as the rarity of these specific events adds complexity to predictive modeling. If ML models lack design considerations for tackling class imbalance, they may become skewed towards one end of the spectrum, making their predictions unreliable. This underscores the significance of addressing the class imbalance challenge within ML. Hence, this review highlights the importance of refining our understanding and application of evaluation methods to navigate the complexities of uncommon outcome predictions more effectively.
2. Inadequate Evaluation Metrics
A classifier can only be as effective as the metric used to assess it. Selecting the wrong metric for model evaluation can lead to suboptimal model training or even mislead the authors into selecting a poor model instead of a better-performing one. Below are metrics that should not be solely relied on for imbalanced classification.
2.1. Accuracy
Accuracy measures how well a model predicts the correct class. It is calculated as the ratio of correct predictions to the total number of predictions. However, when evaluating a binary classification model on an imbalanced dataset, accuracy can be misleading. This is because it only considers the total number of correct predictions without weighing the dataset’s imbalance.
In scenarios with imbalanced datasets, a model consistently predicting the majority class can exhibit high accuracy but may struggle to accurately identify the minority class. When accuracy closely aligns with the class imbalance rate, it suggests the model might be predicting the majority class for all instances. In such cases, the accuracy is driven by the class imbalance, hindering the model’s ability to distinguish between positive and negative classes. Therefore, it is crucial to employ multiple metrics for a comprehensive evaluation of the model’s performance.
2.2. The Area under the ROC Curve (AUROC)
AUROC is calculated as the area under the curve of the true positive rate (TPR) versus the false positive rate (FPR). A no-skill classifier will have a score of 0.5, whereas a perfect classifier will have a score of 1.0.
While AUROC is useful for comparing the performance of different models, it can be misleading with class imbalance as the TPR and FPR are affected by the class distribution.
For instance, in a model predicting a specific disease on an imbalanced dataset, the TPR may be low as the model struggles to predict sick cases, while the FPR may be high because the model accurately predicts healthy cases. In such instances, the AUROC may yield falsely high-performance results.
2.3. Adequate Evaluation Metrics
In assessing a binary classification model on an imbalanced dataset, key metrics include the confusion matrix (CM), F1 score, Matthews correlation coefficient (MCC), and area under the precision-recall curve (AUPRC).
2.4. Confusion Matrix
The CM matrix delineates true positive, true negative, false positive, and false negative in model predictions [7]. This matrix is particularly useful for imbalanced classes, offering insights into the model’s performance on each class separately. It also facilitates the calculations of various metrics such as precision, recall, and F1 score.
As mentioned earlier, relying solely on accuracy is advised against in imbalanced cases, with the confusion matrix providing a strong rationale for that. Researchers can use it to visualize the model’s performance, pinpoint common errors, and make the necessary adjustments to enhance overall performance. displays the metrics provided by the CM.
2.5. F1 Score
Improving the model’s performance often involves aiming for a balance between precision and recall. However, it is essential to acknowledge that there is a trade-off between these two metrics, where enhancement of one metric score can lead to a reduction in the other. The correct balance is highly reliant on the model’s objective and is referred to as the F1 score. The F1 score is particularly useful when faced with imbalanced classes as it emphasizes the harmonic mean between precision and recall [8].
2.6. Matthews Correlation Coefficient (MCC)
The Matthews correlation coefficient (MCC) stands out as a robust metric, especially when dealing with imbalanced class data. MCC is a balanced metric that takes into account all four components of the CM. It is defined as (TP × TN − FP × FN)/sqrt((TP + FP) × (TP + FN) × (TN + FP) × (TN + FN)). The MCC tends to approach +1 in cases of perfect classification and −1 in instances of entirely incorrect classification (inverted classes). When facing class-imbalanced data, the MCC is considered a strong metric due to its effectiveness in capturing various aspects of classification performance. Notably, it remains close to 0 for completely random classifications.
2.7. Informedness (Youden’s J Statistic)
Informedness, also known as Youden’s J statistic, quantifies the difference between the true positive rate (Recall) and the false positive rate (FPR). It is computed as Recall + Specificity − 1, with values ranging from −1 to +1. A higher informedness value signifies a superior classifier [9].
2.8. Markedness
Markedness gauges the difference between the PPV and NPV. The calculation involves adding PPV and NPV, then subtracting 1, resulting in a range from −1 to +1. A higher markedness value suggests a better overall performance in predictive values [9].
2.9. The Area under the Precision-Recall Curve (AUPRC)
AUPRC is a valuable metric when working with imbalanced datasets as it considers precision and recall in its calculation [10]. This is important when dealing with imbalanced datasets where the focus is on identifying positive cases and minimizing false positives. The AUPRC is derived by plotting precision and recall values at various thresholds and then computing the area under the resulting curve.
The resulting curve is formed by different points, and classifiers performing better under different thresholds will be ranked higher. On the plot, a no-skill classifier manifests as a horizontal line with precision proportional to the number of positive examples in the dataset. Conversely, a point in the top right corner signifies a perfect classifier.
2.10. Brier Score (BS)
The Brier Score (BS) serves as a metric for assessing the accuracy of a probabilistic classifier and is used to evaluate the performance of binary classification models [11]. It is determined by calculating the mean squared difference between the predicted probabilities for the positive class and the true binary outcomes. The BS ranges from 0 to 1, with a score of 0 indicating a perfect classifier, while 1 suggests predicted probabilities completely discordant with actual outcomes.
It is important to note that while the BS possesses desirable properties, it does have limitations. For instance, it may favor tests with high specificity in situations where the clinical context requires high sensitivity, especially when the prevalence is low [12].
To address these limitations, a model’s BS evaluation should consider the outcome prevalence in the patient sample, prompting the computation of the null BS. The null BS acts as a benchmark for evaluating a model’s performance by always predicting the most prevalent outcome in the dataset. The model’s BS is then compared to that of the null model, and ΔBrier is calculated by subtracting the null BS from that of the model under evaluation. The ΔBrier is a scalar value and indicates the extent to which the model outperforms the null model. The formula follows ΔBrier = BS of the model − BS of the null model.
2.11. Additional Evaluation Metrics and Graphical Tools
3. Materials and Methods
3.1. Data Sources and Search Strategies
A comprehensive search of several databases was performed on 28 February 2023. Results were limited to the English language but had no date limitations. The databases included Ovid MEDLINE(R), Ovid Embase, Ovid Cochrane Central Register of Controlled Trials, Ovid Cochrane Database of Systematic Reviews, Web of Science Core Collection via Clarivate Analytics, and Scopus via Elsevier. The search strategies were designed and conducted by a medical librarian in collaboration with the study investigators . Controlled vocabulary supplemented with keywords was used. The actual strategies listing all search terms used and how they are combined are available in the . Ultimately, 3340 papers and 121 full-text articles were assessed, resulting in the inclusion of 60 studies (Figure 2) [14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72]. This review was conducted in accordance with the PRISMA guidelines .
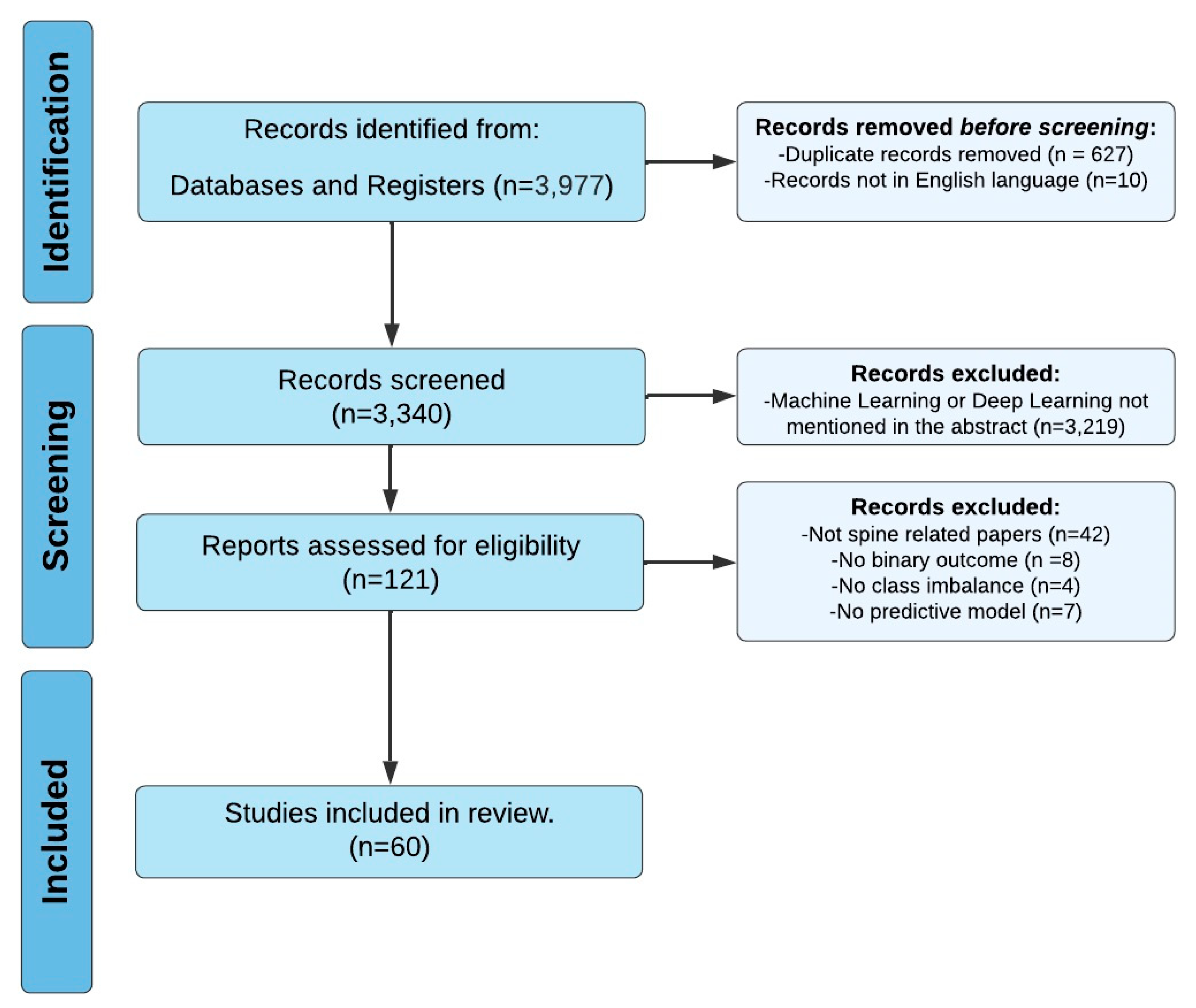
Figure 2. PRISMA Flowchart Illustrating Systematic Review Search Strategy.
3.2. Eligibility Criteria and Data Extraction
Inclusion criteria encompass studies focusing on ML-based prediction models pertaining to binary surgical outcomes following spine surgery. Both intraoperative and postoperative outcomes were eligible. Exclusion criteria comprised studies predicting nonbinary outcomes (e.g., 3+ categorical or numeric outcomes), those predicting non-spine surgical outcomes, studies with balanced outcomes, and those lacking predictive models.
The extracted data from all studies included the first author, paper title, year of publication, spinal pathology and surgery type, sample size, outcome variable (the primary result being measured), imbalance percentage, accuracy, AUROC (area under the receiver operating characteristic curve), sensitivity, specificity, PPV (positive predictive value), NPV (negative predictive value), Brier score (BS), other metrics, dataset, performance, journal, and error type .
3.3. Data Synthesis and Risk of Bias Assessment
Our aim was to investigate the methodologies employed by the included studies, emphasizing the process rather than the outcomes or findings themselves. Accordingly, we refrained from engaging in narrative synthesis, data pooling, risk of bias assessment, or evidence certainty determination. Instead, our review specifically addressed methodologies related to models handling class imbalance.
3.4. Statistical Analysis
Given the considerable heterogeneity between studies, we did not perform a meta-analysis and opted for a qualitative and comprehensive analysis instead. Study characteristics are presented using frequencies and percentages for categorical variables. In cases where studies reported multiple results within a single outcome (e.g., different AUCs per type of complication), the top scores were taken. Metrics were computed for studies that provided a confusion matrix.
4. Results
4.1. Characteristics of the Included Studies
The selected papers cover a variety of outcomes, some focusing on a single target while others address multiple targets. outlines the metrics derived from the confusion matrix. Among the 60 papers, 12 focused on readmissions, 13 predicted lengths of stay (LOS), 12 addressed non-home discharge, 6 estimated mortality, and 5 anticipated reoperations. The models also forecasted a variety of medical and surgical outcomes, as detailed in . The target outcomes exhibited data imbalances ranging from 0.44% to 42.4%. Figure 3 illustrates the growing number of papers in the field over time.
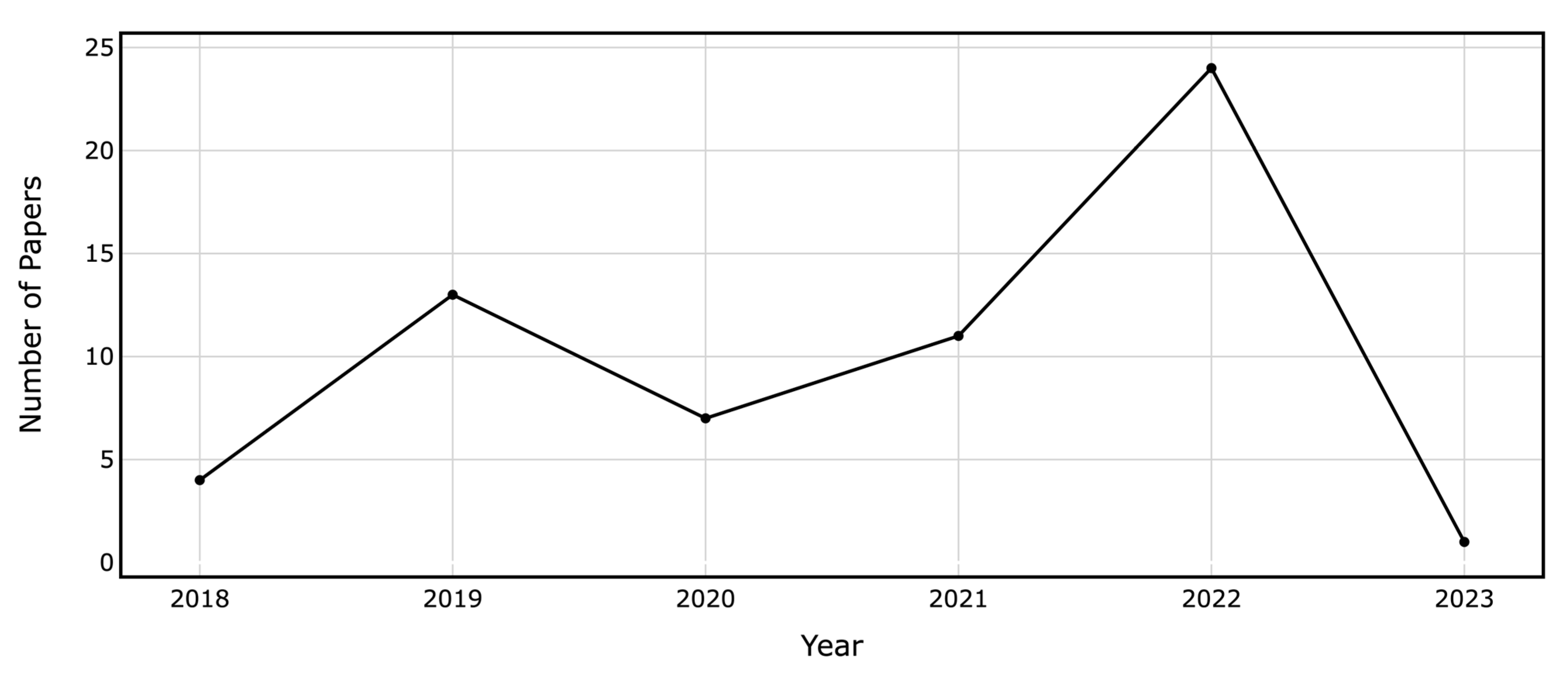
Figure 3. Annual Count of ML and DL Papers on Binary Outcome Prediction in Spine Surgery Included in the Review.
In the analysis of the 60 included papers, 59 reported the model’s AUROC, 28 mentioned accuracies, 33 provided sensitivity, 29 discussed specificity, 28 addressed PPV, 24 considered NPV, 25 indicated BS (with 10 providing null model Brier), and 8 detailed the F1 score. Additionally, a variety of representations and visualizations were presented in these papers: 52 included an AUROC figure, 27 featured a calibration curve, 13 displayed a confusion matrix, 12 showcased decision curves, 3 incorporated PR curves, and only 1 offered a precision-recall curve. Moreover, to train their models, 23 studies utilized NSQIP data, and 19 used single-center data, while the rest used multicenter data or other national datasets. In the following sections, we explore prevalent errors observed in the reviewed articles, highlighting key areas for improvement in the evaluation and reporting of machine learning models in spine surgery applications.
4.2. Error Type I: Incomplete Reporting of Performance Metrics
Han et al. presented models predicting various medical and surgical complications, demonstrating strong performance metrics such as AUROCs, BS, sensitivity, and acceptable specificity [15]. Similarly, Arora et al. developed a well-performing model that predicts patient discharge to rehabilitation, achieving high AUROC, sensitivity, and specificity with an adjusted threshold of 0.16 [32]. Both studies also demonstrated well-calibrated models through calibration plots.
Shah et al. developed models predicting readmission or major complications, achieving satisfactory AUROC, AUPRC, and BS while outperforming the baseline AUPRC, indicating its effectiveness in predicting true positives well [17]. Valliani et al. predicted non-home discharge with remarkable AUROCs, PPV, and NPV. The study also presented a well-calibrated model through a calibration plot, although the plot did not display true probability and predicted risks greater than 0.8 [18]. Despite these models’ solid performance on the metrics reported, studies in this category failed to report other metrics crucial for model evaluation. While some omitted the PPV and NPV, others failed to mention baseline AUPRC, sensitivity, specificity, and the null model BS. Without the inclusion of all the necessary evaluation metrics, the assessment lacks validity, even when reported metrics show high performance.
4.3. Error Type IIA: Metric Optimization at the Expense of Others
Li et al. developed artificial neural networks (ANN) and random forest (RF) models for predicting day-of-surgery patient discharge. The ANN model exhibited high sensitivity but low specificity, while the RF model showed the opposite [26]. Kim et al. and Arvind et al. presented models predicting mortality, wound complications, venous thromboembolism, and cardiac complications [30,31,34]. The Linear regression (LR) models exhibited high specificities at the expense of extremely low sensitivities. In contrast, ANN displayed high sensitivities and specificities but low PPVs. Goyal et al. developed models predicting non-home discharge and 30-day unplanned readmission [24]. The models predicting non-home discharge achieved high AUROCs, accuracies, sensitivity, specificity, and NPV but low PPV, leading to many false positives. This training method is advised only when the target is critically important and should not be missed, even if it means encountering many false positives.
Stopa et al. and Karhade et al. trained models to predict non-routine discharge, presenting high AUROC, BS, specificity, and NPV but low sensitivity and PPV [21,25]. Although both models demonstrated well-calibrated performance via calibration plots, they struggled to detect positive cases correctly, facing low sensitivity scores and PPVs. Moreover, both papers presented a decision curve demonstrating that their models are better than the treat-all or the treat-non approach.
4.4. Error Type IIB: High Accuracy and AUROC but Poor Sensitivity
Cabrera et al. developed models that predict extended LOS, readmission, reoperation, infection, and transfusion. Although these models achieved high accuracies, their sensitivities were generally low, except for the model predicting transfusion [14]. Gowd et al. predicted multiple surgical outcomes with high AUROCs and NPV but low PPV and extremely low sensitivity scores [19]. Kalagara et al. trained models to predict unplanned readmission, reporting high accuracies but low sensitivities, while specificity, PPV, and NPV were not provided [22]. Hopkins et al. developed a readmission prediction model with high accuracy, AUROC, specificity, PPV, and NPV but low sensitivity, indicating an inability to identify a significant proportion of true positive instances [23].
4.5. Other Errors
In addition to the previously mentioned errors, some papers provided poor calibration plots and omitted essential metrics. Kuris et al., Veeramani et al., and Zhang et al. presented models predicting readmission, unplanned re-intubation, and short LOS, respectively, with acceptable AUROCs, accuracies, and BSs [16,27,29]. However, all three studies provided calibration plots indicating poor calibration, as the calibration curves were not in proximity to the near-perfect prediction diagonal. Moreover, the null model BS was not reported. Ogink et al. developed models predicting non-home discharge displaying adequate AUROCs and BSs [33]. Nevertheless, the calibration plots in both studies revealed that the models were not well-calibrated for larger observed proportions and predicted probabilities, as the calibration curves drifted away from the near-perfect prediction diagonal. Furthermore, these five papers failed to report sensitivities, specificities, PPVs, and NPVs.
5. Discussion
ML’s ability to predict future events by training on vast healthcare data has attracted substantial interest [73]. Nevertheless, predicting rare events poses significant challenges attributed to the skewed data distribution. To address this issue, techniques for imbalanced class learning have been designed. This paper focuses on showcasing the application of ML in predicting uncommon patterns or events within the realm of spinal surgeries. These surgeries encompass various risks and require a thorough assessment of potential outcomes, such as readmission, reoperation, ELOS, and discharges to non-home settings [74,75].
We reviewed 60 papers addressing post-spinal surgery outcome predictions, examining specific elements of spinal surgeries such as pathologies, surgical procedures, and spinal levels. However, a limited number of these studies adequately evaluated their models using suitable metrics for imbalanced data binary classification tasks. This observation highlights the need for more rigorous model evaluation methods to ensure their clinical reliability and effectiveness in rare-event predictions. In a study by Haixiang et al., it was revealed that 38% of the 517 papers addressing imbalanced classification across various domains used accuracy as an evaluation metric despite the authors’ awareness of dealing with an imbalanced problem [76]. In some instances, the accuracy of a proposed method might be lower than the class imbalance ratio, implying that a dummy classifier solely predicting the majority class would yield better performance.
The importance of appropriate evaluation metrics for imbalanced classification problems in machine learning cannot be overstated. Our analysis revealed that many papers relied on inadequate evaluation metrics. Moreover, our review identified instances where models optimized one metric at the expense of others. These practices can lead to misinterpretation of model performance and hinder clinical applicability. Therefore, it is crucial to conduct a comprehensive evaluation of classifier performance, addressing all relevant metrics rather than focusing on only one or two. Additionally, striking a balance between the various performance metrics is essential to ensure that models can be effectively employed in clinical decision-making. By emphasizing the need for a holistic approach to classifier evaluation, our study encourages the development of more robust and reliable ML models for predicting rare outcomes in spinal surgery and other healthcare applications.
Training a binary classification model on an imbalanced dataset, where one class significantly outnumbers the other, poses challenges as the model may be biased towards the more prevalent class. Most strategies addressing this issue can be applied in the preprocessing stage prior to model training. These strategies include undersampling the majority class, oversampling the minority class, modifying weights, and optimizing thresholds.
Undersampling involves reducing instances of the majority class in the training sample to equalize the classes. Various undersampling techniques, such as random undersampling, NearMiss, cluster-based undersampling, and Tomek links, can balance a dataset. Random undersampling selects a subset of majority class examples randomly, while NearMiss retains examples from the majority class closest to the minority class [77]. Cluster-based undersampling sorts majority class examples into clusters and selects a representative subset from each cluster. Tomek links remove examples from the majority class closely related to minority class examples, increasing the space between classes and facilitating classification [78].
Another method for balancing classes is oversampling, which entails adding more minority class examples to the training dataset. For binary classification, strategies such as random oversampling, the synthetic minority over-sampling technique (SMOTE), and adaptive synthetic sampling (ADASYN) can be employed. Random oversampling adds random minority class samples to the training set until classes are equal, potentially leading to overfitting if the oversampled data does not represent the original minority class distribution. SMOTE, a more advanced technique, creates synthetic samples using the k-nearest neighbors algorithm to ensure new samples resemble original minority class samples [79]. ADASYN is similar to SMOTE but generates synthetic samples more representative of the feature space region where the minority class is under-represented. While oversampling techniques appear more promising than undersampling ones, especially with small datasets, it is important to note that oversampling involves the addition of synthetic data that might not correspond to the real data. Given this constraint, advanced generative deep-learning algorithms were developed [80,81]. One such advancement is generative adversarial network synthesis for oversampling (GANSO), which has demonstrated superior performance compared to the synthetic minority oversampling technique (SMOTE) [82].
In addition to the sampling methods discussed, threshold optimization can enhance classification model performance by adjusting the decision threshold for identifying positive category cases [83]. This involves calculating the model’s performance at various thresholds and selecting the one with the best performance. It is essential to conduct this optimization on a separate validation set to avoid overfitting. Once the optimal threshold is determined, it can be applied to a model’s predictions on new data.
It is good practice to systematically test various suitable algorithms for the task at hand. Decision tree algorithms, such as random forest (RF), classification and regression tree (CART), and C4, perform well with imbalanced datasets. Additionally, classifiers’ performance can be enhanced by assigning weights based on the inverse of class frequencies or using advanced techniques like cost-sensitive learning. In place of traditional classification models, anomaly detection models can also be used. Ensemble methods, such as bagging and boosting, are also effective in handling imbalanced data. Finally, it is crucial to evaluate using appropriate metrics for imbalanced classification tasks, such as MCC, CM, precision, recall, F1 score, and AUPRC. By employing a diverse set of metrics and considering the unique characteristics of each dataset, researchers can avoid being misled by metrics like accuracy and AUROC.
6. Conclusions
This systematic review summarizes the current literature on ML and DL in spine surgery outcome prediction. Evaluating these models is crucial for their successful integration into clinical practice, especially given the imbalanced nature of spine surgery predicted outcomes. The 60 papers reviewed focused on binary outcomes such as ELOS, readmissions, non-home discharge, mortality, and reoperations. The review highlights the prevalent use of the AUROC metric in 59 papers. Other metrics like sensitivity, specificity, PPV, NPV, Brier score, and F1 score were inconsistently reported.
Based on the findings of this review, our recommendations for future research in ML applications for spine surgery are threefold. First, we advocate for the comprehensive use and reporting of all appropriate evaluation metrics to ensure a holistic assessment of model performance. Second, developing strategies to optimize classifier performance on imbalanced data is crucial. Third, we stress the necessity of increasing awareness among researchers, reviewers, and editors about the pitfalls associated with inadequate model evaluation. To improve peer review quality, we suggest including at least one ML specialist in the review process of medical AI papers, as a high level of model design scrutiny is not a realistic demand from clinician reviewers.
The significance of proper evaluation schemes in applied ML cannot be overstated. Embracing these recommendations as the field advances will undoubtedly facilitate the integration of reliable and effective ML models in clinical settings. Ultimately, integrating such models in the clinical setting will contribute to improved patient outcomes, surgical decision-making, and medical management in spine surgery.
References
- Chang, M.; Canseco, J.A.; Nicholson, K.J.; Patel, N.; Vaccaro, A.R. The Role of Machine Learning in Spine Surgery: The Future Is Now. Front. Surg. 2020, 7, 54. [Google Scholar] [CrossRef] [PubMed]
- El-Hajj, V.G.; Gharios, M.; Edström, E.; Elmi-Terander, A. Artificial Intelligence in Neurosurgery: A Bibliometric Analysis. World Neurosurg. 2023, 171, 152–158.e4. [Google Scholar] [CrossRef] [PubMed]
- Harris, E.P.; MacDonald, D.B.; Boland, L. Personalized perioperative medicine: A scoping review of personalized assessment and communication of risk before surgery. Can. J. 2019, 66, 1026–1037. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Saravi, B.; Hassel, F.; Ülkümen, S.; Zink, A.; Shavlokhova, V.; Couillard-Despres, S.; Boeker, M.; Obid, P.; Lang, G. Artificial intelligence-driven prediction modeling and decision making in spine surgery using hybrid machine learning models. J. Pers. Med. 2022, 12, 509. [Google Scholar] [CrossRef]
- Guo, X.; Yin, Y.; Dong, C.; Yang, G.; Zhou, G. On the Class Imbalance Problem. In Proceedings of the 2008 Fourth International Conference on Natural Computation, Jinan, China, 18–20 October 2008; pp. 192–201. [Google Scholar]
- Hong, C.S.; Oh, T.G. TPR-TNR plot for confusion matrix. Commun. Stat. Appl. Methods 2021, 28, 161–169. [Google Scholar] [CrossRef]
- Van Rijsbergen, C.J.; Van Rijsbergen, C.J.K. Information Retrieval, Butterworth-Heinemann. J. Librariansh. 1979, 11, 237. [Google Scholar]
- Ruopp, M.D.; Perkins, N.J.; Whitcomb, B.W.; Schisterman, E.F. Youden Index and Optimal Cut-Point Estimated from Observations Affected by a Lower Limit of Detection. Biom. J. 2008, 50, 419–430. [Google Scholar] [CrossRef]
- Davis, J.; Goadrich, M. The Relationship Between Precision-Recall and ROC Curves. In Proceedings of the 23rd International Conference on Machine Learning, ACM, Pittsburgh, PA, USA, 25–29 June 2006. [Google Scholar] [CrossRef]
- Huang, C.; Li, S.-X.; Caraballo, C.; Masoudi, F.A.; Rumsfeld, J.S.; Spertus, J.A.; Normand, S.-L.T.; Mortazavi, B.J.; Krumholz, H.M. Performance Metrics for the Comparative Analysis of Clinical Risk Prediction Models Employing Machine Learning. Circ. Cardiovasc. Qual. Outcomes 2021, 14, 1076–1086. [Google Scholar] [CrossRef]
- Assel, M.; Sjoberg, D.D.; Vickers, A.J. The Brier score does not evaluate the clinical utility of diagnostic tests or prediction models. Diagn. Progn. Res. 2017, 1, 19. [Google Scholar] [CrossRef]
- Salazar, A.; Vergara, L.; Vidal, E. A proxy learning curve for the Bayes classifier. Pattern Recognit. 2023, 136, 109240. [Google Scholar] [CrossRef]
- Cabrera, A.; Bouterse, A.; Nelson, M.; Razzouk, J.; Ramos, O.; Chung, D.; Cheng, W.; Danisa, O. Use of random forest machine learning algorithm to predict short term outcomes following posterior cervical decompression with instrumented fusion. J. Clin. Neurosci. 2023, 107, 167–171. [Google Scholar] [CrossRef] [PubMed]
- Han, S.S.; Azad, T.D.; Suarez, P.A.; Ratliff, J.K. A machine learning approach for predictive models of adverse events following spine surgery. Spine J. 2019, 19, 1772–1781. [Google Scholar] [CrossRef] [PubMed]
- Kuris, E.O.; Veeramani, A.; McDonald, C.L.; DiSilvestro, K.J.; Zhang, A.S.; Cohen, E.M.; Daniels, A.H. Predicting Readmission After Anterior, Posterior, and Posterior Interbody Lumbar Spinal Fusion: A Neural Network Machine Learning Approach. World Neurosurg. 2021, 151, e19–e27. [Google Scholar] [CrossRef] [PubMed]
- Shah, A.A.; Devana, S.K.; Lee, C.; Bugarin, A.; Lord, E.L.; Shamie, A.N.; Park, D.Y.; van der Schaar, M.; SooHoo, N.F. Prediction of Major Complications and Readmission After Lumbar Spinal Fusion: A Machine Learning–Driven Approach. World Neurosurg. 2021, 152, e227–e234. [Google Scholar] [CrossRef]
- Valliani, A.A.; Kim, N.C.; Martini, M.L.; Gal, J.S.; Neifert, S.N.; Feng, R.; Geng, E.A.; Kim, J.S.; Cho, S.K.; Oermann, E.K.; et al. Robust Prediction of Non-home Discharge After Thoracolumbar Spine Surgery With Ensemble Machine Learning and Valida-tion on a Nationwide Cohort. World Neurosurg. 2022, 165, e83–e91. [Google Scholar] [CrossRef]
- Gowd, A.K.; O’Neill, C.N.; Barghi, A.; O’Gara, T.J.; Carmouche, J.J. Feasibility of Machine Learning in the Prediction of Short-Term Outcomes Following Anterior Cervical Discectomy and Fusion. World Neurosurg. 2022, 168, e223–e232. [Google Scholar] [CrossRef]
- Ogink, P.T.; Karhade, A.V.; Thio, Q.C.B.S.; Hershman, S.H.; Cha, T.D.; Bono, C.M.; Schwab, J.H. Development of a machine learning algorithm predicting discharge placement after surgery for spondylolisthesis. Eur. Spine J. 2019, 28, 1775–1782. [Google Scholar] [CrossRef]
- Karhade, A.V.; Ogink, P.; Thio, Q.; Broekman, M.; Cha, T.; Gormley, W.B.; Hershman, S.; Peul, W.C.; Bono, C.M.; Schwab, J.H. Development of machine learning algorithms for prediction of discharge disposition after elective inpatient surgery for lumbar degenerative disc disorders. Neurosurg. Focus 2018, 45, E6. [Google Scholar] [CrossRef]
- Kalagara, S.; Eltorai, A.E.M.; Durand, W.M.; DePasse, J.M.; Daniels, A.H. Machine learning modeling for predicting hospital re-admission following lumbar laminectomy. J. Neurosurg. Spine 2018, 30, 344–352. [Google Scholar] [CrossRef]
- Hopkins, B.S.; Yamaguchi, J.T.; Garcia, R.; Kesavabhotla, K.; Weiss, H.; Hsu, W.K.; Smith, Z.A.; Dahdaleh, N.S. Using machine learning to predict 30-day readmissions after posterior lumbar fusion: An NSQIP study involving 23,264 patients. J. Neurosurg. Spine 2019, 32, 399–406. [Google Scholar] [CrossRef] [PubMed]
- Goyal, A.; Ngufor, C.; Kerezoudis, P.; McCutcheon, B.; Storlie, C.; Bydon, M. Can machine learning algorithms accurately predict discharge to nonhome facility and early unplanned readmissions following spinal fusion? Analysis of a national surgical registry. J. Neurosurg. Spine 2019, 31, 568–578. [Google Scholar] [CrossRef] [PubMed]
- Stopa, B.M.; Robertson, F.C.; Karhade, A.V.; Chua, M.; Broekman, M.L.D.; Schwab, J.H.; Smith, T.R.; Gormley, W.B. Predicting nonroutine discharge after elective spine surgery: External validation of machine learning algorithms. J. Neurosurg. Spine 2019, 31, 742–747. [Google Scholar] [CrossRef] [PubMed]
- Li, Q.; Zhong, H.; Girardi, F.P.; Poeran, J.; Wilson, L.A.; Memtsoudis, S.G.; Liu, J. Machine Learning Approaches to Define Candidates for Ambulatory Single Level Laminectomy Surgery. Glob. Spine J. 2022, 12, 1363–1368. [Google Scholar] [CrossRef] [PubMed]
- Veeramani, A.; Zhang, A.S.; Blackburn, A.Z.; Etzel, C.M.; DiSilvestro, K.J.; McDonald, C.L.; Daniels, A.H. An Artificial Intelligence Approach to Predicting Unplanned Intubation Following Anterior Cervical Discectomy and Fusion. Glob. Spine J. 2022, 13, 1849–1855. [Google Scholar] [CrossRef] [PubMed]
- DiSilvestro, K.J.; Veeramani, A.; McDonald, C.L.; Zhang, A.S.; Kuris, E.O.; Durand, W.M.; Cohen, E.M.; Daniels, A.H. Predicting Postoperative Mortality After Metastatic Intraspinal Neoplasm Excision: Development of a Machine-Learning Approach. World Neurosurg. 2021, 146, e917–e924. [Google Scholar] [CrossRef] [PubMed]
- Zhang, A.S.; Veeramani, A.; Quinn, M.S.; Alsoof, D.; Kuris, E.O.; Daniels, A.H. Machine Learning Prediction of Length of Stay in Adult Spinal Deformity Patients Undergoing Posterior Spine Fusion Surgery. J. Clin. Med. 2021, 10, 4074. [Google Scholar] [CrossRef]
- Kim, J.S.; Merrill, R.K.; Arvind, V.; Kaji, D.; Pasik, S.D.; Nwachukwu, C.C.; Vargas, L.; Osman, N.S.; Oermann, E.K.; Caridi, J.M.; et al. Examining the Ability of Artificial Neural Networks Machine Learning Models to Accurately Predict Complications Following Posterior Lumbar Spine Fusion. Spine 2018, 43, 853–860. [Google Scholar] [CrossRef]
- Arvind, V.; Kim, J.S.; Oermann, E.K.; Kaji, D.; Cho, S.K. Predicting Surgical Complications in Adult Patients Undergoing Anterior Cervical Discectomy and Fusion Using Machine Learning. Neurospine 2018, 15, 329–337. [Google Scholar] [CrossRef]
- Arora, A.B.; Lituiev, D.; Jain, D.; Hadley, D.; Butte, A.J.; Berven, S.; Peterson, T.A. Predictive Models for Length of Stay and Discharge Disposition in Elective Spine Surgery: Development, Validation, and Comparison to the ACS NSQIP Risk Calculator. Spine 2023, 48, E1–E13. [Google Scholar] [CrossRef]
- Ogink, P.T.; Karhade, A.V.; Thio, Q.C.B.S.; Gormley, W.B.; Oner, F.C.; Verlaan, J.J.; Schwab, J.H. Predicting discharge placement after elective surgery for lumbar spinal stenosis using machine learning methods. Eur. Spine J. 2019, 28, 1433–1440. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.S.; Arvind, V.; Oermann, E.K.; Kaji, D.; Ranson, W.; Ukogu, C.; Hussain, A.K.; Caridi, J.; Cho, S.K. Predicting Surgical Complications in Patients Undergoing Elective Adult Spinal Deformity Procedures Using Machine Learning. Spine Deform. 2018, 6, 762–770. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Wan, D.; Chen, M.; Li, Y.; Ying, H.; Yao, G.; Liu, Z.; Zhang, G. Automated machine learning-based model for the prediction of delirium in patients after surgery for degenerative spinal disease. CNS Neurosci. Ther. 2023, 29, 282–295. [Google Scholar] [CrossRef] [PubMed]
- Yang, B.; Gao, L.; Wang, X.; Wei, J.; Xia, B.; Liu, X.; Zheng, P. Application of supervised machine learning algorithms to predict the risk of hidden blood loss during the perioperative period in thoracolumbar burst fracture patients complicated with neurological compromise. Front. Public Health 2022, 10, 969919. [Google Scholar] [CrossRef] [PubMed]
- Xiong, C.; Zhao, R.; Xu, J.; Liang, H.; Zhang, C.; Zhao, Z.; Huang, T.; Luo, X. Construct and Validate a Predictive Model for Surgical Site Infection after Posterior Lumbar Interbody Fusion Based on Machine Learning Algorithm. Comput. Math. Methods Med. 2022, 2022, 2697841. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Lei, L.; Ji, M.; Tong, J.; Zhou, C.-M.; Yang, J.-J. Predicting postoperative delirium after microvascular decompression surgery with machine learning. J. Clin. Anesth. 2020, 66, 109896. [Google Scholar] [CrossRef] [PubMed]
- Wang, K.Y.; Ikwuezunma, I.; Puvanesarajah, V.; Babu, J.; Margalit, A.; Raad, M.; Jain, A. Using Predictive Modeling and Supervised Machine Learning to Identify Patients at Risk for Venous Thromboembolism Following Posterior Lumbar Fusion. Glob. Spine J. 2021, 13, 1097–1103. [Google Scholar] [CrossRef]
- Wang, H.; Tang, Z.-R.; Li, W.; Fan, T.; Zhao, J.; Kang, M.; Dong, R.; Qu, Y. Prediction of the risk of C5 palsy after posterior laminectomy and fusion with cervical myelopathy using a support vector machine: An analysis of 184 consecutive patients. J. Orthop. Surg. Res. 2021, 16, 332. [Google Scholar] [CrossRef]
- Wang, H.; Fan, T.; Yang, B.; Lin, Q.; Li, W.; Yang, M. Development and Internal Validation of Supervised Machine Learning Algo-rithms for Predicting the Risk of Surgical Site Infection Following Minimally Invasive Transforaminal Lumbar Interbody Fusion. Front. Med. 2021, 8, 771608. [Google Scholar] [CrossRef]
- Valliani, A.A.; Feng, R.; Martini, M.L.; Neifert, S.N.; Kim, N.C.; Gal, J.S.; Oermann, E.K.; Caridi, J.M. Pragmatic Prediction of Excessive Length of Stay After Cervical Spine Surgery With Machine Learning and Validation on a National Scale. Neurosurgery 2022, 91, 322–330. [Google Scholar] [CrossRef]
- Siccoli, A.; de Wispelaere, M.P.; Schröder, M.L.; Staartjes, V.E. Machine learning–based preoperative predictive analytics for lumbar spinal stenosis. Neurosurg. Focus 2019, 46, E5. [Google Scholar] [CrossRef] [PubMed]
- Shah, A.A.; Devana, S.K.; Lee, C.; Bugarin, A.; Lord, E.L.; Shamie, A.N.; Park, D.Y.; van der Schaar, M.; SooHoo, N.F. Machine learning-driven identification of novel patient factors for prediction of major complications after posterior cervical spinal fusion. Eur. Spine J. 2022, 31, 1952–1959. [Google Scholar] [CrossRef] [PubMed]
- Saravi, B.; Zink, A.; Ülkümen, S.; Couillard-Despres, S.; Hassel, F.; Lang, G. Performance of Artificial Intelligence-Based Algorithms to Predict Prolonged Length of Stay after Lumbar Decompression Surgery. J. Clin. Med. 2022, 11, 4050. [Google Scholar] [CrossRef]
- Russo, G.S.; Canseco, J.A.; Chang, M.; Levy, H.A.; Nicholson, K.; Karamian, B.A.; Mangan, J.; Fang, T.; Vaccaro, A.R.; Kepler, C.K. A Novel Scoring System to Predict Length of Stay After Anterior Cervical Discectomy and Fusion. J. Am. Acad. Orthop. Surg. 2021, 29, 758–766. [Google Scholar] [CrossRef] [PubMed]
- Rodrigues, A.J.B.; Schonfeld, E.B.; Varshneya, K.B.; Stienen, M.N.M.; Staartjes, V.E.; Jin, M.C.B.; Veeravagu, A. Comparison of Deep Learning and Classical Machine Learning Algorithms to Predict Postoperative Outcomes for Anterior Cervical Discectomy and Fusion Procedures With State-of-the-art Performance. Spine 2022, 47, 1637–1644. [Google Scholar] [CrossRef] [PubMed]
- Ren, G.; Liu, L.; Zhang, P.; Xie, Z.; Wang, P.; Zhang, W.; Wang, H.; Shen, M.; Deng, L.; Tao, Y.; et al. Machine Learning Predicts Recurrent Lumbar Disc Herniation Following Percutaneous Endoscopic Lumbar Discectomy. Glob. Spine J. 2022, 14, 25. [Google Scholar] [CrossRef] [PubMed]
- Porche, K.; Maciel, C.B.; Lucke-Wold, B.; Robicsek, S.A.; Chalouhi, N.; Brennan, M.; Busl, K.M. Preoperative prediction of postoperative urinary retention in lumbar surgery: A comparison of regression to multilayer neural network. J. Neurosurg. Spine 2022, 36, 32–41. [Google Scholar] [CrossRef]
- Pedersen, C.F.; Andersen, M.; Carreon, L.Y.; Eiskjær, S. Applied Machine Learning for Spine Surgeons: Predicting Outcome for Patients Undergoing Treatment for Lumbar Disc Herniation Using PRO Data. Glob. Spine J. 2022, 12, 866–876. [Google Scholar] [CrossRef]
- Nunes, A.A.; Pinheiro, R.P.; Costa, H.R.T.; Defino, H.L.A. Predictors of hospital readmission within 30 days after surgery for thoracolumbar fractures: A mixed approach. Int. J. Health Plan. Manag. 2022, 37, 1708–1721. [Google Scholar] [CrossRef]
- Merali, Z.G.; Witiw, C.D.; Badhiwala, J.H.; Wilson, J.R.; Fehlings, M.G. Using a machine learning approach to predict outcome after surgery for degenerative cervical myelopathy. PLoS ONE 2019, 14, e0215133. [Google Scholar] [CrossRef]
- Martini, M.L.; Neifert, S.N.B.; Oermann, E.K.; Gilligan, J.T.; Rothrock, R.J.; Yuk, F.J.; Gal, J.S.; Nistal, D.A.B.; Caridi, J.M. Application of Cooperative Game Theory Principles to Interpret Machine Learning Models of Nonhome Discharge Following Spine Surgery. Spine 2021, 46, 803–812. [Google Scholar] [CrossRef] [PubMed]
- Khan, O.; Badhiwala, J.H.; A Akbar, M.; Fehlings, M.G. Prediction of Worse Functional Status After Surgery for Degenerative Cervical Myelopathy: A Machine Learning Approach. Neurosurgery 2021, 88, 584–591. [Google Scholar] [CrossRef] [PubMed]
- Barber, S.M.; Fridley, J.S.; Gokaslan, Z.L. Commentary: Development of Machine Learning Algorithms for Prediction of 30-Day Mortality After Surgery for Spinal Metastasis. Neurosurgery 2019, 85, E92–E93. [Google Scholar] [CrossRef] [PubMed]
- Karhade, A.V.; Thio, Q.C.B.S.; Ogink, P.T.; A Shah, A.; Bono, C.M.; Oh, K.S.; Saylor, P.J.; Schoenfeld, A.J.; Shin, J.H.; Harris, M.B.; et al. Development of Machine Learning Algorithms for Prediction of 30-Day Mortality After Surgery for Spinal Metastasis. Neurosurgery 2019, 85, E83–E91. [Google Scholar] [CrossRef] [PubMed]
- Karhade, A.V.; Ogink, P.T.; Thio, Q.C.; Cha, T.D.; Gormley, W.B.; Hershman, S.H.; Smith, T.R.; Mao, J.; Schoenfeld, A.J.; Bono, C.M.; et al. Development of machine learning algorithms for prediction of prolonged opioid prescription after surgery for lumbar disc herniation. Spine J. 2019, 19, 1764–1771. [Google Scholar] [CrossRef] [PubMed]
- Karhade, A.V.; Ogink, P.T.; Thio, Q.C.; Broekman, M.L.; Cha, T.D.; Hershman, S.H.; Mao, J.; Peul, W.C.; Schoenfeld, A.J.; Bono, C.M.; et al. Machine learning for prediction of sustained opioid prescription after anterior cervical discectomy and fusion. Spine J. 2019, 19, 976–983. [Google Scholar] [CrossRef] [PubMed]
- Karhade, A.V.; Fenn, B.; Groot, O.Q.; Shah, A.A.; Yen, H.-K.; Bilsky, M.H.; Hu, M.-H.; Laufer, I.; Park, D.Y.; Sciubba, D.M.; et al. Development and external validation of predictive algorithms for six-week mortality in spinal metastasis using 4,304 patients from five institutions. Spine J. 2022, 22, 2033–2041. [Google Scholar] [CrossRef]
- Karhade, A.V.; Cha, T.D.; Fogel, H.A.; Hershman, S.H.; Tobert, D.G.; Schoenfeld, A.J.; Bono, C.M.; Schwab, J.H. Predicting prolonged opioid prescriptions in opioid-naïve lumbar spine surgery patients. Spine J. 2020, 20, 888–895. [Google Scholar] [CrossRef]
- Karhade, A.V.; Bongers, M.E.; Groot, O.Q.; Cha, T.D.; Doorly, T.P.; Fogel, H.A.; Hershman, S.H.; Tobert, D.G.; Srivastava, S.D.; Bono, C.M.; et al. Development of machine learning and natural language processing algorithms for preoperative prediction and automated identification of intraoperative vascular injury in anterior lumbar spine surgery. Spine J. 2021, 21, 1635–1642. [Google Scholar] [CrossRef]
- Karhade, A.V.; Shin, D.; Florissi, I.; Schwab, J.H. Development of predictive algorithms for length of stay greater than one day after one- or two-level anterior cervical discectomy and fusion. Semin. Spine Surg. 2021, 33, 100874. [Google Scholar] [CrossRef]
- Karabacak, M.; Margetis, K. A Machine Learning-Based Online Prediction Tool for Predicting Short-Term Postoperative Outcomes Following Spinal Tumor Resections. Cancers 2023, 15, 812. [Google Scholar] [CrossRef]
- Jin, M.C.; Ho, A.L.; Feng, A.Y.; Medress, Z.A.; Pendharkar, A.V.; Rezaii, P.; Ratliff, J.K.; Desai, A.M. Prediction of Discharge Status and Readmissions after Resection of Intradural Spinal Tumors. Neurospine 2022, 19, 133–145. [Google Scholar] [CrossRef] [PubMed]
- Jain, D.; Durand, W.B.; Burch, S.; Daniels, A.; Berven, S. Machine Learning for Predictive Modeling of 90-day Readmission, Major Medical Complication, and Discharge to a Facility in Patients Undergoing Long Segment Posterior Lumbar Spine Fusion. Spine 2020, 45, 1151–1160. [Google Scholar] [CrossRef] [PubMed]
- Hopkins, B.S.; Mazmudar, A.; Driscoll, C.; Svet, M.; Goergen, J.; Kelsten, M.; Shlobin, N.A.; Kesavabhotla, K.; A Smith, Z.; Dahdaleh, N.S. Using artificial intelligence (AI) to predict postoperative surgical site infection: A retrospective cohort of 4046 posterior spinal fusions. Clin. Neurol. Neurosurg. 2020, 192, 105718. [Google Scholar] [CrossRef] [PubMed]
- Fatima, N.; Zheng, H.; Massaad, E.; Hadzipasic, M.; Shankar, G.M.; Shin, J.H. Development and Validation of Machine Learning Algorithms for Predicting Adverse Events After Surgery for Lumbar Degenerative Spondylolisthesis. World Neurosurg. 2020, 140, 627–641. [Google Scholar] [CrossRef] [PubMed]
- Etzel, C.M.; Veeramani, A.; Zhang, A.S.; McDonald, C.L.; DiSilvestro, K.J.; Cohen, E.M.; Daniels, A.H. Supervised Machine Learning for Predicting Length of Stay After Lumbar Arthrodesis: A Comprehensive Artificial Intelligence Approach. J. Am. Acad. Orthop. Surg. 2022, 30, 125–132. [Google Scholar] [CrossRef]
- Elsamadicy, A.A.; Koo, A.B.; Reeves, B.C.; Cross, J.L.; Hersh, A.; Hengartner, A.C.; Karhade, A.V.; Pennington, Z.; Akinduro, O.O.; Lo, S.-F.L.; et al. Utilization of Machine Learning to Model Important Features of 30-day Readmissions following Surgery for Metastatic Spinal Column Tumors: The Influence of Frailty. Glob. Spine J. 2022, 2022. 190, 13. [Google Scholar] [CrossRef]
- Dong, S.-T.; Zhu, J.; Yang, H.; Huang, G.; Zhao, C.; Yuan, B. Development and Internal Validation of Supervised Machine Learning Algorithm for Predicting the Risk of Recollapse Following Minimally Invasive Kyphoplasty in Osteoporotic Vertebral Com-pression Fractures. Front. Public Health 2022, 10, 874672. [Google Scholar] [CrossRef]
- Dong, S.; Zhu, Y.; Yang, H.; Tang, N.; Huang, G.; Li, J.; Tian, K. Evaluation of the Predictors for Unfavorable Clinical Outcomes of Degenerative Lumbar Spondylolisthesis After Lumbar Interbody Fusion Using Machine Learning. Front. Public Health 2022, 10, 835938. [Google Scholar] [CrossRef]
- Yen, H.-K.; Ogink, P.T.; Huang, C.-C.; Groot, O.Q.; Su, C.-C.; Chen, S.-F.; Chen, C.-W.; Karhade, A.V.; Peng, K.-P.; Lin, W.-H.; et al. A machine learning algorithm for predicting prolonged postoperative opioid prescription after lumbar disc herniation surgery. An external validation study using 1316 patients from a Taiwanese cohort. Spine J. 2022, 22, 1119–1130. [Google Scholar] [CrossRef]
- Weiss, P. Rare Events. Sci. News 2003, 163, 227. [Google Scholar] [CrossRef]
- Reis, R.C.; de Oliveira, M.F.; Rotta, J.M.; Botelho, R.V. Risk of Complications in Spine Surgery: A Prospective Study. Open Orthop. J. 2015, 9, 20–25. [Google Scholar] [CrossRef] [PubMed]
- Licina, A.; Silvers, A.; Laughlin, H.; Russell, J.; Wan, C. Pathway for enhanced recovery after spinal surgery-a systematic review of evidence for use of individual components. BMC Anesthesiol. 2021, 21, 74. [Google Scholar] [CrossRef] [PubMed]
- Guo, H.; Li, Y.; Shang, J.; Gu, M.; Huang, Y.; Gong, B. Learning from class-imbalanced data: Review of methods and applications. Expert Syst. Appl. 2017, 73, 220–239. [Google Scholar] [CrossRef]
- Tanimoto, A.; Yamada, S.; Takenouchi, T.; Sugiyama, M.; Kashima, H. Improving imbalanced classification using near-miss instances. Expert Syst. Appl. 2022, 201, 117130. [Google Scholar] [CrossRef]
- Zeng, M.; Zou, B.; Wei, F.; Liu, X.; Wang, L. Effective prediction of three common diseases by combining SMOTE with Tomek links technique for imbalanced medical data. In Proceedings of the 2016 IEEE International Conference of Online Analysis and Computing Science (ICOACS), Chongqing, China, 28–29 May 2016; pp. 225–228. [Google Scholar]
- Blagus, R.; Lusa, L. SMOTE for high-dimensional class-imbalanced data. BMC Bioinform. 2013, 14, 106. [Google Scholar] [CrossRef]
- Figueira, A.; Vaz, B. Survey on Synthetic Data Generation, Evaluation Methods and GANs. Mathematics 2022, 10, 2733. [Google Scholar] [CrossRef]
- de Giorgio, A.; Cola, G.; Wang, L. Systematic review of class imbalance problems in manufacturing. J. Manuf. Syst. 2023, 71, 620–644. [Google Scholar] [CrossRef]
- Salazar, A.; Vergara, L.; Safont, G. Generative Adversarial Networks and Markov Random Fields for oversampling very small training sets. Expert Syst. Appl. 2020, 163, 113819. [Google Scholar] [CrossRef]
- Yogi, A.; Dey, R. Class Imbalance Problem in Data Science: Review. Int. Res. J. Comput. Sci. 2022, 9, 56–60. [Google Scholar] [CrossRef]